PISA es una evaluación internacional de una complejidad enorme, pero que tiene la ventaja de ser extremadamente transparente, ya que publica prácticamente todo: buena parte de las preguntas, estudios muy extensos y detallados, los métodos utilizados y las bases de datos completas que utilizan. Todo ello se puede encontrar aquí. La evaluación se pasa cada tres años desde su primera edición en 2000, y estamos a la espera de que se publiquen los datos de su cuarta entrega, la correspondiente a 2012 (saldrá a principios de diciembre de 2013).
Desde hace unos cuantos años, trabajo con los datos de PISA. La primera edición de la cual descargué las bases de datos fue la de 2003, y desde entonces he ido manejando los datos tanto de la anterior (2000) como de las siguientes, según han ido saliendo. Como algunas tablas son bastante grandes, las suelo cargar en una base de datos (habitualmente MySQL) para comenzar a utilizarlas. Cuando estuvieron disponibles las bases de datos de 2009, ya tenía creadas todas las anteriores, e intenté aprovechar el diseño previo para la nueva base de datos de 2009, ya que los campos no varían mucho.
La tabla grande de 2009 (la que tiene los datos principales de los alumnos) tiene casi medio millón de registros y más de 400 campos, unas dimensiones considerables, y tarda bastante en migrar. Pueden imaginar mi cabreo cuando, pasados cerca del 80% de los datos, el programa da un error: un valor es demasiado alto para el rango reservado en la base de datos. Después de investigar un rato, el error venía de que un alumno había obtenido en la escala de matemáticas más de 1000 puntos PISA, mientras que en mi base de datos tenía reservado sólo espacio para números de tres cifras (entre 0 y 999). Eso me obligó a modificar el tamaño de más de treinta campos en la base de datos y otras modificaciones menores en el programa de migración, y comenzar de nuevo el proceso. Y, como el alumno en cuestión vivía en Shanghai, pues se quedó con el mote de chino cudeiro.
Además de su rendimiento en Matemáticas, podemos saber por los datos de PISA que el chino cudeiro es un chaval que va a una escuela de Secundaria básica en Shanghai, China, que cursa noveno grado (el equivalente a nuestro 3º de ESO: sí, va un curso retrasado, probablemente porque en China ingresen en el curso por la edad que tienen al comenzarlo, y no por el año natural, como en España), que nació en octubre de 1993, que cursó más de un año de educación infantil, comenzó la Primaria con seis años, que vive en casa con sus padres y, al menos, un abuelo, pero que -muy probablemente- no tiene hermanos. Su madre estudió hasta el Bachillerato y trabaja a tiempo completo en una oficina, mientras que el padre obtuvo una licenciatura y tiene un alto cargo en una gran empresa. Ambos nacieron en China (en la propia Shanghai), y hablan chino en casa. En su hogar dispone de los recursos educativos y los electrodomésticos típicos de cualquier hogar de clase media occidental (libros de literatura, poesía, de referencia técnica, diccionario, y algunas obras de arte; también un ordenador, habitación propia,lavaplatos, DVD, aspiradora, cámara digital y exprimidora) salvo internet. Además, en casa hay dos móviles, un televisor, un coche, y sólo tienen un baño. No hay demasiados libros (entre 25 y 100), pero el chino cudeiro lee al menos dos horas diarias, pues es uno de sus pasatiempos favoritos. Lee sobre todo libros de no ficción, literatura, poesía y periódicos, pero casi nunca cómics o revistas. No se concecta a internet, ni en casa (que no tiene) ni fuera de casa, por lo que no chatea ni usa el correo electrónico: sólo lo utiliza en la biblioteca del colegio para cuestiones relacionadas con el estudio. Tiene estrategias de estudio razonables, pero no especialmente buenas y, como cualquier chaval, a veces no entiende las cosas y se atasca en el estudio. Tiene seis clases semanales de matemáticas en el colegio, con una duración de 40 minutos cada una. En una semana tiene en total 38 clases (unas 25 horas semanales), y no tiene clases de refuerzo ni dentro ni fuera de la escuela. Se pasa, eso sí, todos los días por la biblioteca, para estudiar y hacer los deberes, y alguna vez simplemente para leer. Para estudiar, suele hacer resúmenes y leerlos varias veces, pero no copia, ni subraya, ni lee en voz alta. Estudia matemáticas cuatro horas a la semana, pero no sabemos cuánto dedica al resto de asignaturas. Sus resultados son excepcionales en Matemáticas, pero distan mucho de ser brillantes en Lectura. Aparentemente, un chaval como otro buen estudiante cualquiera.
Las escalas de rendimiento en PISA tienen una media de 500 y una desviación típica de 100, por lo que para que un alumno obtuviese más de 1000 puntos en PISA tendría que obtener un rendimiento cinco desviaciones típicas por encima de la media. Asumiendo que los resultados de PISA se distribuyen normalmente, la probabilidad de encontrar un alumno por encima de los 1000 puntos es de 2,87e-07 (0,000000287). Para que me entienda todo el mundo, uno de cada 3,5 millones de alumnos. Tenía cierta razón en suponer que ningún alumno pasaría de los 1000 puntos. Para que os hagáis una idea de la distancia que media entre el chino cudeiro y la media de los países desarrollados, aquí os dejo el siguiente gráfico:

Las barras azules representan la distribución real de los alumnos de países de la OCDE en Matemáticas (PV1MATH) en 2009, la línea en forma de campana de Gauss es la distribución teórica que utiliza PISA (media 500 y desviación típica 100, asumiendo normalidad), y la línea amarilla de la derecha es la puntuación del chino cudeiro en la escala. En realidad, PISA no obtiene las puntuaciones reales de los alumnos -no es un examen-, sino las "puntuaciones poblacionales", es decir, no está hecha para valorar la capacidad del individuo sino para conocer los resultados de una población, por lo que no sabemos la puntuación real de nuestro chino cudeiro, sino que es una aproximación algo inexacta. Pero, para este blog y para el juego que nos traemos entre manos, podemos darla por válida. El resto de distribuciones y datos empleados en esta anotación sí que son válidos incluso siguiendo criterios académicos, salvo que, por simplificar, se usa sólo la primera escala de Matemáticas (PV1MATH), y no las cinco que usa PISA.
Por tanto, tendríamos una posibilidad entre 3,5 millones de encontrar un estudiante de este nivel de excelencia en los países de la OCDE. Pero es que nuestro chino cudeiro no estudia en un país de la OCDE, sino que estudia en Shanghai, que tiene un sistema educativo algo particular y donde se hace especial hincapié en el aprendizaje de las Matemáticas. En el siguiente gráfico, que mantiene la misma escala que el anterior, podemos ver la distribución real de los alumnos españoles (barras azules) y de los chinos (barras amarillas) en Matemáticas en PISA 2009, además de la distribución teórica media de PISA y la situación del chino cudeiro (las frecuencias de los gráficos han sido calculadas simulando poblaciones iguales para poder establecer comparaciones).
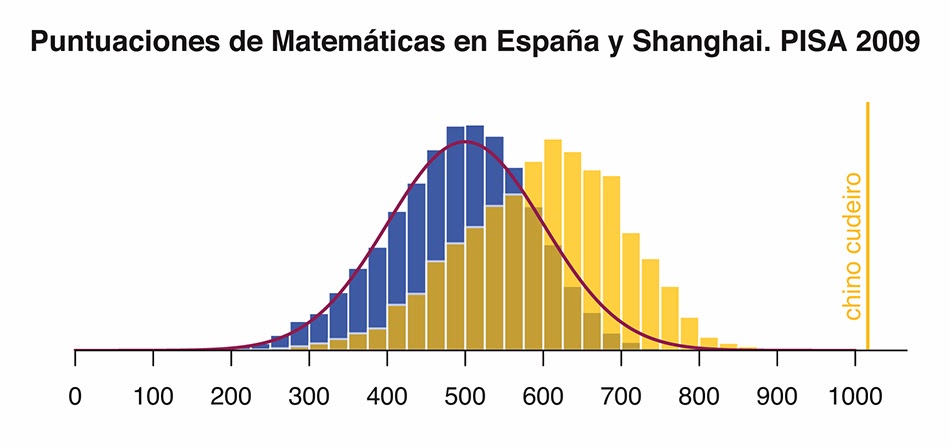
El rendimiento del chino cudeiro sigue siendo excepcional, pero ya parece más probable encontrar un alumno así. De hecho, para los parámetros teóricos de la distribución de Shanghai, la probabilidad de encontrar un alumno por encima de los 1000 puntos en Matemáticas es de 4.95e-05 (0,0000495), que puede parecer todavía muy pequeña, pero ya es razonable: más o menos, uno de cada 20.000 alumnos. Para que se hagan una idea, la probabilidad de encontrar un alumno que estudie en el sistema educativo español por encima de los 1000 puntos en Matemáticas es de 2,36e-08 (0,0000000236), uno de cada 42 millones. Creo que no existe tanto español como para tener una sola posibilidad de que eso ocurra.
Pero no acaba aqui la cosa. El chino cudeiro no estudia sólo en un sistema educativo, sino en un centro concreto. Uno bastante bueno, pero ni siquiera es el que mejores resultados obtiene en Shanghai, donde hay un puñado de escuelas con niveles similares. En el siguiente gráfico se pueden ver las distribuciones teóricas -las reales, al haber muy pocos alumnos, están bastante dispersas- del centro típico de la OCDE, del mejor centro que tenemos en España y del centro donde estudia el chino cudeiro.

En el gráfico se ve que el chino cudeiro sigue siendo excepcional, pero se entiende mejor que en un centro con una media en Matemáticas por encima de 700 puntos exista la posibilidad de encontrar a un alumno así. De hecho, la probabilidad de encontrar un alumno por encima de los 1000 puntos en un centro con la distribución teórica del suyo es ya de sólo 0,00123, poco más o menos de uno cada 800 alumnos. Si además tenemos en cuenta que nada menos que 14 de los 152 centros (un 9%) evaluados en Shanghai tenían una media por encima de los 700 puntos, es fácil colegir que esta ciudad china tenía bastantes posibilidades de tener un alumno así. Los que no tenemos ninguna oportunidad somos nosotros: la probabilidad de que aparezca un alumno de ese nivel en el centro español con mejores resultados es de 6.23e-07 (0,000000623), una entre 1,6 millones de alumnos.
Hay quien todavía piensa que las grandes cabezas nacen, y que por tanto es una cuestión de suerte. Sin embargo, hoy sabemos que las grandes cabezas nacen en muchos sitios, pero que sólo en algunos se les da la oportunidad de aprovechar de verdad su potencial.


En nuestro país, como tú bien sabes, las prioridades de la educación van por un camino bien distinto al de las matemáticas que, después de todo, no dejan de ser una cosa fría, abstracta y que nadie entiende.
ResponderEliminarAunque no está directamente relacionado con el tema (o sí) podemos consultar la clasificación de la fase final de la Olipiada Matemática Internacional.
ResponderEliminarhttp://www.imo-official.org/year_country_r.aspx?year=2013
Primer clasificado, cómo no, China. A continuación el pelotón de los Dragones junto con Rusia (quién tuvo retuvo) y unos cuantos países occidentales bien situados: Estados Unidos, Reino Unido, Canadá... aunque , atención, si clicamos sobre estos últimos países citados descubrimos que....
¡¡¡Hay mucho nombre con sabor oriental de por medio y muy pocos nombres anglosajones o siquiera occidentales!!!
Otro dato no sé si curioso: el equipo finés consigue unos modestos 46 puntos. ¡El mejor sistema educativo del mundo, como nos recuerdan nuestros políticos constantemente, es incapaz o, lo que es peor, no se preocupa de la formación matemática de sus mejores cerebros!
Añado al anterior comentario:
ResponderEliminarEl factor tamaño (de la población) juega a favor de China y en contra de Finlandia. Con todo, uno se esperaría del equipo finés unos resultados sensiblemente mejores que los que finalmente consiguieron (casi 20 puntos por debajo del Reino de España).
Emilio, el problema es que en lectura o ciencias pasa lo mismo. No es que las matemáticas no sean una prioridad, es que el que un alumno sepa no es una prioridad en España. Uno de los problemas fundamentales es que aún no se ha entendido que se tomó este camino para reducir el fracaso escolar, entre otras cosas, pero que ese es el camino que conduce al fracaso escolar, además de a otros callejones sin salida.
ResponderEliminarJ. Saavedra, el finés no es el mejor sistema educativo del mundo, es extraordinario en conseguir unos estándares medios muy altos en lectura, pero es bastante torpe en Matemáticas, sobre todo en cálculo, comparado con los asiáticos. Tampoco es excesivamente bueno en promover la excelencia. Un apunte sobre su capacidad de cálculo, aquí:
http://akarlin.com/2013/07/22/scandinavians-cant-do-fractions/
Europa [Occidental] decidió hace décadas que sus habitantes no tenían por qué saber calcular correctamente, y así nos va. A hora se ha puesto de moda enseñar Matemáticas con métodos orientales (ábaco y cosas así), pero la razón por la que los asiáticos tienen mejores resultados en matemáticas se debe exclusivamente a que tienen un programa orientado a saber más matemáticas, y el resto no.
De acuerdo contigo José Manuel, en mi comentario me referí a las matemáticas pero del mismo modo me podría haber referido a la lectura o a las ciencias como tú señalas. Lo que yo observo en diferentes foros educativos es que la pregunta que cada vez más gente se hace es: constatándose una y otra vez que nuestro sistema educativo no va, qué fuerzas son las que están frenando e imposibilitando que a esto comience a ponérsele remedio. Qué es lo que hace que haya tantos que den por bueno lo que sucede y que finalmente piensen que estamos donde nos corresponde.
ResponderEliminarEmilio, siento contestarte tan tarde, pero quería haber hecho una anotación más extensa para responderte. En fin, no ha podido ser, entre otras cosas porque aún no tengo claras las cosas. Pero sí sé que es un fenómeno extendido por muchos países, y que tiene detrás un impulso ideológico fuerte que facilita su implantación y diluye sus consecuencias. Esta ideología, que vamos a denominar "antiintelectualista", está detrás de ideas como que al alumno hay que ayudarle en vez de enseñarle, la desprofesionalización docente o de que la calidad es cualquier cosa menos que un alumno aprenda, y es asombrosamente eficaz a la hora de conseguir que personas que no comparten tal ideología sean valedoras y/o ejecutoras de sus planteamientos.
ResponderEliminarLo multiforme de este movimiento lo demuestra su capacidad para informar buena parte de las políticas tanto de la izquierda como de la derecha moderadas de buena parte de Europa (y otros países), y de conseguir, dado su carácter mimético, que los enemigos del antiintelectualismo en ambos partidos achaquen al partido contrario los logros antiintelectualistas, sin ver nunca al enemigo que tienen en casa. Por ejemplo, que gente inteligente de izquierdas considere que Bolonia es "neoliberal" y se queden tan anchos, cuando es un evidente parto de los sectores antiintelectuales de la izquierda y la derecha aliados es bastante sintomático.
Me temo que hasta que los anti-antiintelectualistas no detecten y combatan a los antiintelectualistas de su propio partido, en vez de atacar a los de enfrente, no vamos a conseguir demasiado.
En mi opinion mientras se legisle sobre educación desde el Ministerio de Sanidad y se entienda que lo que nuestros alumnos ahora mismo necesitan son más lecciones sobre como combatir el sexismo y la violencia de género, y que frente a eso las matemáticas y la lengua son cuestiones secundarias, no solo seguiremos en el pozo que estamos sino que lo ahondaremos.
ResponderEliminarEste comentario ha sido eliminado por el autor.
ResponderEliminarHola, José Manuel.
ResponderEliminarPrimero quería felicitarte por tu blog. Es complicado encontrar sitios donde te ofrezcan información basada en datos, y no en prejuicios ideológicos, tanto de un lado como del otro.
Después de leer varios de los post que le dedicas a PISA, me he animado a descargarme las BBDD para explorarlas y hacerles algunas preguntas. Me defiendo con SPSS y R, así que me he descargado las BBDD en .txt y la sintaxis en .sps correspondiente para obtener los archivos .sav, y migrarlos posteriormente a R, en caso necesario. Lo cierto es que, después de leer en este post que utilizas MySQL, pensé que iba a ser complicado mover las BBDD más grandes (INT_STU12_DEC03 y INT_COG12_DEC03) con mi ordenador y un "simple" SPSS, pero la verdad es que no he tenido problemas para crear los ficheros .sav y realizar algunos análisis descriptivos básicos.
Me gustaría saber por qué utilizas MySQL, ¿qué ventaja te aporta a la hora de analizar datos? (como verás, no tengo idea de bases de datos, sólo sé manejar software de análisis de datos).
Por otro lado, aunque me voy a leer la documentación disponible para comprender las BBDD, me puedes dar algún tip para comenzar a trabajar con ellas. Por ejemplo, para el análisis que haces en "El suicidio de Europa...", entiendo que has tenido que unir las distintas BBDD (al menos algunas de ellas). ¿Debería comenzar uniendo las BBDD, o los análisis interesantes se pueden realizar sin necesidad de unirlas?
Muchas gracias por anticipado y un saludo.
Gracias, giltrapo.
ResponderEliminarHace años utilizaba MySQL para manejar las BBDD de PISA, porque venía del mundo de las bases de datos y porque los ordenadores de entonces no eran los de ahora, y porque entonces no conocía R. Ahora utilizo R, y además me hice hace tiempo una librería de análisis para los errores típicos de PISA bastante optimizada, que publicaré algún día de estos (cosas básicas: medias, dt, frecuencias, regresiones lineales y logísticas...). El problema es meter los nulos en R, con archivos muy grandes no es demasiado eficiente, pero después ganas mucho tiempo.Normalmente junto las BBDD de alumnos y centros, porque suelo utilizar variables de ambos, y otras veces junto los cognitivos con los de alumnos para otros tipo de análisis. El problema de manejar SPSS es calcular las replicaciones, que es algo pesado, y con archivos grandes se podía quedar colgado, pero para análisis menos precisos sirve igualmente y lo mismo te es más cómodo.
Para analizar PISA es esencial el manual técnico. Hay una versión excelentemente traducida de 2003, en la web del INE, y del resto en inglés en la web de PISA. La primera, para entender los valores plausibles y cómo calcular los errores típicos, es lo más sencillo. Para detalles, los demás. En fin, si quieres enlaces, algún programa de R o tienes cualquier duda, director en ifie . es. La dirección anda por el blog, pero así no tienes que buscarla.
Perdón, INEE (Instituto Nacional de Evaluación Educativa), no INE.
EliminarMuchas gracias por tu respuesta, José Manuel.
EliminarMe he descargado "PISA Data Analysis Manual: SPSS and SAS, Second Edition", y aprovecharé este fin de semana para leérmelo.
He estado importando el .sav a R, y me ha dado bastante warnings relativos a la memoria y a las etiquetas de algunas variables. La verdad es que, para mi sorpresa, no logro que la BBDD corra en R tan suavemente como en SPSS. Seguiré probando.
No entiendo bien lo de "meter los nulos en R", ni lo de "calcular las replicaciones" con SPSS, pero imagino que cuando me meta en harina lo entenderé.
Muchas gracias de nuevo por tu atención, y saludos.
Meter los nulos es poner NAs en los valores no válidos de PISA (habitualmente 7,8,9, pero depende), que es una cuestión sencilla pero que en frames de 500x500.000 puede tardar bastante. Las "replicaciones" es el procedimiento estandar para calcular los errores típicos de cualquier estadístico: no se hace como habitualmente, sino calculando el mismo estadístico con 80 pesos diferentes y juntándolos todos (ya lo verás en el manual).
ResponderEliminarSi trabajas en windows te recomiendo utilizar la versión de 64 bits y aumentar la memoria de R ("memory.size(20000)", por ejemplo) antes de cargar el frame.
Gracias de nuevo, José Manuel.
ResponderEliminarAyer estuve pegándome todo el día con la BBDD de estudiantes, y parece que la voy domando poco a poco. Estoy aprendiendo muchas cosas sobre la marcha, como, por ejemplo, que importar directamente desde el archivo .por que genera SPSS, sin asegurarte primero de quitar las etiquetas de las variables, te puede dar muchos quebraderos de cabeza a la hora de graficar con ggplot2.
Por otro lado, respecto a lo que comentas de los nulos, creo que al importar desde SPSS me los contabiliza directamente como NAs. Por ejemplo, al hacer un table de la variable ST15Q01 (Mother current Job Status), me aparecen únicamente las frecuencias de las opciones 1, 2, 3 y 4. Para ver cuantos NAs hay en esa variable tengo que hacerlo a través de un is.na. Entiendo entonces que no hace falta que haga eso que comentabas de poner NAs en los valores no válidos, no?
También llevo bastante avanzado el manual técnico (ayer estuve toda la tarde sin el peque y me pude dedicar a esto en exclusiva). El diseño muestral es bastante complejo, y nunca había utilizado métodos de replicación para obtener estadísticos, pero el manual es muy didáctico y espero no tener problemas en la aplicación de los métodos que propone.
Quizá sea abusar de tu amabilidad, pero ¿sería posible que me facilitases algún correo al que poder escribirte si me encuentro con algún escollo que no pueda resolver?¿O prefieres que te escriba en los comentarios de alguno de tus post?
Muchas gracias de nuevo y saludos.
Yo no lo importé desde SPSS, sino desde el archivo de texto original. La próxima vez pruebo como dices.
ResponderEliminarPara contabilizar los NA prueba mejor:
>table(pisa12$ST15Q01, useNA="ifany")
Mi correo te lo facilité en el primer comentario que te envié: director en ifie punto es. Escríbeme cuando quieras.
Brutal el termino "Chino Cudeiro"! Es lamentable que a estas alturas nadie del gobierno haya podido llegar a estas conclusiones. Con los datos que aportas hablan por si solos! Incluso para un ministro que no superara el informe PISA ;)
ResponderEliminarLos políticos llegaron hace tiempo a estas conclusiones. Pero ni tienen interés en arreglar el problema ni tienen incentivos para ello. Padres que se quejan porque su hijo no aprueba conozco por millares. Que se quejen de que su hijo no aprenda lo bastante, pocos y con la boca pequeña. No es que no vean el problema: es que si nadie se queja, no hay problema.
ResponderEliminar